Preventif dan Korektif Maintenance Infrastruktur Sistem Informasi
Pemantauan stabilitas sistem informasi dilakukan secara real-time menggunakan Dashboard Grafana, dengan fokus utama pada sumber daya server. Pemeliharaan preventif perangkat keras dilaksanakan setiap 3 bulan, sedangkan peremajaan infrastruktur dilakukan dalam siklus 5 tahun.
Optimalisasi Kinerja Database
Prosedur kerja untuk memastikan kinerja database optimal dan penanganan event performa.
Tujuan: Memastikan kinerja database tetap optimal dan menangani kasus yang mempengaruhi kinerja.
Ruang Lingkup: Pemeriksaan berkala, penanganan node mati, penambahan resource, dan restart node.
Node Database: Titik jaringan atau anggota dalam database terdistribusi yang menyimpan sebagian data.
Resource: Sumber daya komputasi yang dibutuhkan oleh node database (CPU, RAM, Storage).
- 1DB Admin memeriksa kinerja database secara berkala.
- 2DB Admin menunggu informasi dari PM Dev jika ada case atau event yang mempengaruhi kinerja database.
- 3Jika ada case atau event, PM Dev menginfokan ke DB Admin bahwa ada case atau event.
- 4DB Admin memeriksa setiap node database (termasuk write read).
- 5DB Admin memeriksa apakah ada node yang mati.
- 6Jika ada node yang mati, DB Admin memeriksa apakah resourcenya cukup.
- 7Jika cukup, DB Admin melakukan restart node database.
- 8Jika tidak, DB Admin menambahkan resource terlebih dahulu baru melakukan restart node database.
- 9DB Admin menginfokan ke PM Dev bahwa node database sudah siap.
- 10PM Dev memeriksa node databasenya.
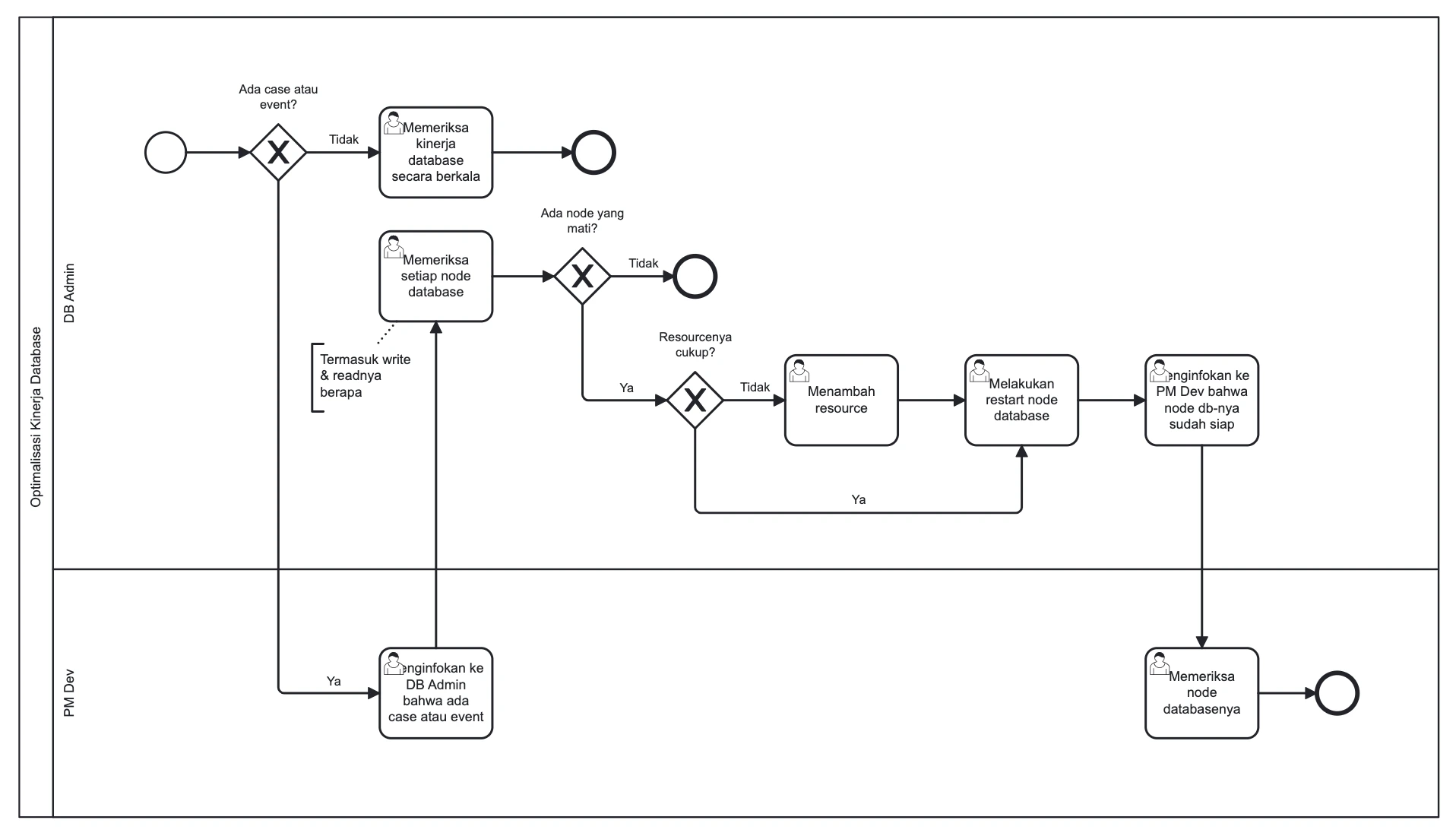
Gambar 1: Diagram Alur Kerja (BPMN) Optimalisasi Kinerja Database
Maintenance HPC (High Performance Computing)
Prosedur pengelolaan permintaan dan instalasi paket untuk sistem komputasi berkinerja tinggi.
Tujuan: Prosedur ini bertujuan untuk memastikan bahwa semua permintaan terkait High Performance Computing (HPC) dari klien diterima, diproses, dan diselesaikan dengan benar serta efisien.
Ruang Lingkup: Prosedur ini mencakup seluruh proses mulai dari penerimaan permintaan dari klien, penerusan permintaan ke Sys Admin, instalasi paket yang dibutuhkan klien, hingga penyampaian hasil kembali ke klien.
HPC (High Performance Computing): Sistem komputasi berkinerja tinggi yang digunakan untuk memproses data yang kompleks dengan cepat.
Sys Admin: Administrator sistem yang bertanggung jawab atas manajemen dan pemeliharaan sistem HPC.
IT Support: Tim pendukung teknologi informasi yang membantu dalam penerimaan dan pengalihan permintaan terkait HPC.
- 1IT Support menerima permintaan dari Client terkait HPC.
- 2IT Support meneruskan permintaan tersebut ke Sys Admin.
- 3Sys Admin melakukan instalasi paket yang dibutuhkan sesuai dengan permintaan Client.
- 4Sys Admin menginformasikan hasil instalasi ke IT Support.
- 5IT Support meneruskan informasi hasil instalasi ke Client.
- 6Client menerima hasil instalasi.
Gambar 2: Diagram Alur Kerja (BPMN) Maintenance HPC
Maintenance Virtual Machine
Prosedur identifikasi masalah dan perbaikan resource (Disk/RAM) pada layanan Virtual Machine.
Tujuan: Memastikan layanan Virtual Machine (VM) tetap berjalan normal dengan melakukan identifikasi masalah, pengecekan resource mesin fisik, dan tindakan perbaikan yang diperlukan.
Ruang Lingkup: Mencakup identifikasi masalah VM, pengecekan resource (disk dan RAM), penambahan kapasitas disk (extend volume), penambahan RAM, serta memastikan service berjalan normal kembali.
VM (Virtual Machine): Mesin virtual yang menjalankan sistem operasi dan aplikasi seolah-olah berada di komputer fisik.
Resource Mesin Fisik: Kapasitas fisik server yang digunakan oleh VM (Disk, RAM).
Disk Penuh: Kondisi di mana kapasitas penyimpanan disk VM mencapai batasnya.
RAM Out-of-Memory: Kondisi di mana penggunaan RAM VM mencapai batas kapasitas.
Extend Volume: Proses menambah kapasitas penyimpanan pada VM dari dalam sistem operasi.
- 1Sys Admin mendapati Service VM dalam kondisi mati.
- 2Sys Admin melakukan identifikasi jenis permasalahan.
-
3
Skenario A: Disk Penuh
Tindakan awal: Sys Admin memeriksa ketersediaan resource pada mesin fisik.
Jika Resource Fisik Cukup:- Sys Admin menambah kapasitas disk VM.
- Melakukan extend volume di dalam OS VM.
- Memastikan kapasitas disk bertambah.
- Memastikan service berjalan normal.
Jika Resource Fisik Tidak Cukup:Sys Admin melakukan prosedur "Maintenance Storage Disk".
-
4
Skenario B: RAM Out-of-Memory
Tindakan awal: Sys Admin memeriksa ketersediaan resource pada mesin fisik.
Jika Resource Fisik Cukup:- Sys Admin mematikan VM.
- Menambah kapasitas RAM VM.
- Menghidupkan VM kembali.
- Memastikan service berjalan normal.
Jika Resource Fisik Tidak Cukup:Sys Admin melakukan prosedur "Maintenance Storage RAM".
Gambar 3: Diagram Alur Kerja (BPMN) Maintenance Virtual Machine
Maintenance Storage Disk
Prosedur penanganan masalah fisik disk pada server untuk memastikan ketersediaan sistem.
Tujuan: Memastikan setiap masalah terkait disk pada server fisik dapat diidentifikasi dan ditangani dengan tepat waktu dan efektif, guna memastikan ketersediaan dan kinerja optimal dari sistem server.
Ruang Lingkup: Mencakup langkah-langkah yang harus diambil oleh Sys Admin dalam menangani masalah disk yang rusak atau kekurangan kapasitas pada server fisik, termasuk identifikasi masalah, penanganan disk, dan memastikan sistem kembali berfungsi dengan normal.
Sys Admin: Petugas yang bertanggung jawab atas pemeliharaan dan perbaikan server fisik.
Disk Rusak: Kondisi dimana disk tidak dapat berfungsi dengan baik atau mengalami kerusakan fisik.
Hot Swap: Proses mengganti disk yang rusak dengan disk baru tanpa mematikan server.
Hypervisor: Perangkat lunak yang memungkinkan pembuatan dan manajemen mesin virtual.
- 1Sys Admin menerima notifikasi atau mendeteksi adanya masalah pada disk fisik.
- 2Sys Admin mengidentifikasi jenis masalah: Disk Rusak atau Kapasitas Penuh.
-
3
Skenario A: Penanganan Disk Rusak
Tindakan: Sys Admin memeriksa dukungan fitur Hot Swap pada server.
Jika Server Mendukung Hot Swap:- Sys Admin mencabut disk yang rusak secara langsung.
- Memasang disk baru (Hot Swap).
- Memantau proses rebuilding RAID hingga selesai.
Jika Server Tidak Mendukung Hot Swap:- Sys Admin mematikan server fisik (Shutdown).
- Melakukan penggantian disk secara manual.
- Menghidupkan kembali server.
- Memastikan Hypervisor mendeteksi disk baru dan sistem berjalan normal.
-
4
Skenario B: Kekurangan Kapasitas
- Sys Admin menambahkan disk fisik baru pada slot yang tersedia.
- Mengonfigurasi disk baru ke dalam array penyimpanan (RAID/LVM).
- Melakukan expand datastore pada level Hypervisor.
- Mengonfirmasi bahwa kapasitas penyimpanan keseluruhan telah bertambah.
- 5Sys Admin memverifikasi bahwa sistem server dan VM berjalan normal tanpa error.
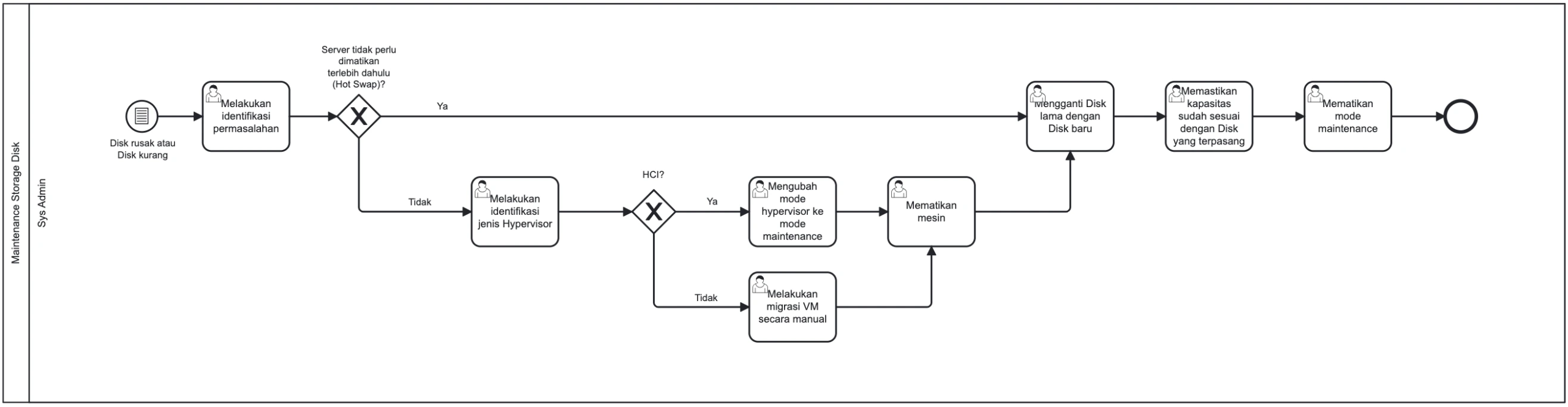
Gambar 4: Diagram Alur Kerja (BPMN) Maintenance Storage Disk
Maintenance Server Fisik (RAM)
Prosedur penggantian dan pengecekan kapasitas memori (RAM) pada infrastruktur server fisik.
Tujuan: Memastikan proses maintenance RAM pada server fisik berjalan dengan efisien dan sesuai dengan standar yang telah ditetapkan, mulai dari identifikasi masalah RAM hingga penggantian dan pengecekan kapasitas RAM.
Ruang Lingkup: Mencakup langkah-langkah yang dilakukan oleh Sys Admin dalam melakukan maintenance RAM pada server fisik, termasuk identifikasi hypervisor, penggantian RAM, dan pengecekan kapasitas RAM.
RAM (Random Access Memory): Memori utama yang digunakan oleh server untuk menyimpan data sementara saat server sedang beroperasi.
Hypervisor: Perangkat lunak atau perangkat keras yang membuat dan menjalankan mesin virtual.
HCI (Hyper-Converged Infrastructure): Sistem infrastruktur IT yang menggabungkan penyimpanan, komputasi, dan jaringan ke dalam satu sistem.
VM (Virtual Machine): Mesin virtual yang menjalankan sistem operasi dan aplikasi seperti layaknya komputer fisik.
- 1Sys Admin mengidentifikasi masalah pada RAM (kerusakan hardware) atau kebutuhan upgrade kapasitas.
-
2Persiapan pada Cluster HCI / Hypervisor
Sebelum mematikan server fisik, Sys Admin harus mengamankan workload yang berjalan.
- Sys Admin mengidentifikasi Hypervisor host target.
- Melakukan migrasi VM (Live Migration) ke host lain dalam cluster.
- Mengaktifkan Maintenance Mode pada host tersebut untuk mencegah VM kembali secara otomatis.
-
3Eksekusi Maintenance Fisik
- Sys Admin melakukan Shutdown pada server fisik.
- Membuka chassis server dan mengidentifikasi slot RAM target.
- Melakukan penggantian modul RAM yang rusak atau menambah modul baru.
- Menutup chassis dan memastikan semua komponen terpasang rapat.
- 4Sys Admin menghidupkan kembali server fisik (Power On).
- 5Masuk ke BIOS/UEFI atau antarmuka manajemen (iDRAC/ILO) untuk memverifikasi kapasitas RAM baru telah terdeteksi tanpa error.
-
6Finalisasi & Pemulihan Sistem
- Sys Admin menonaktifkan Maintenance Mode pada Hypervisor.
- Memastikan status node kembali Healthy pada dashboard HCI.
- Melakukan pengecekan kapasitas total pada cluster.
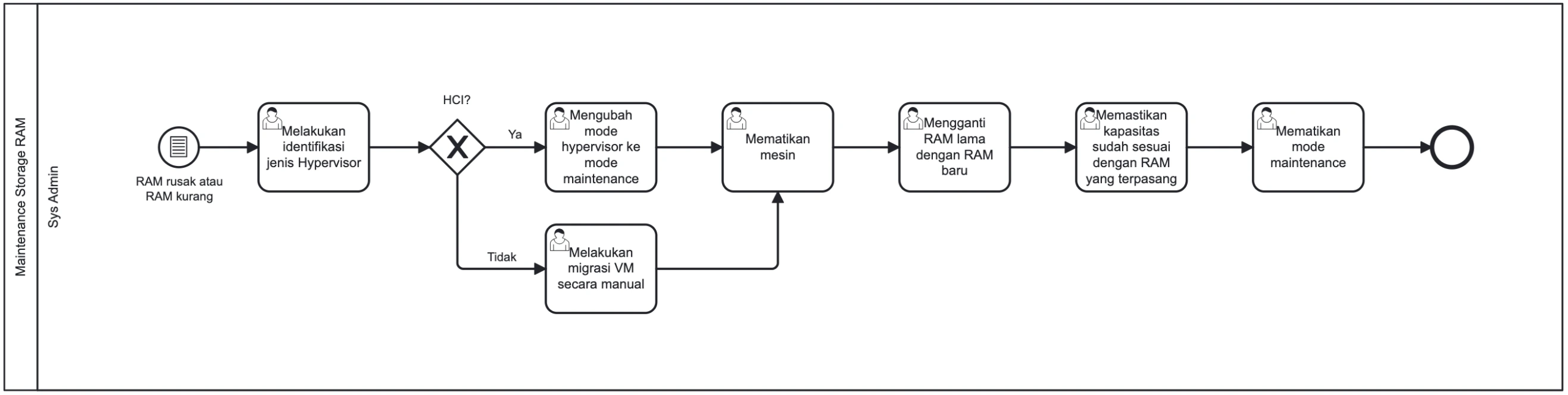
Gambar 5: Diagram Alur Kerja (BPMN) Maintenance RAM Server Fisik
Maintenance Shared Hosting
Prosedur penanganan masalah layanan hosting Plesk (Disk, Miskonfigurasi, dan Keamanan).
Tujuan: Prosedur kerja ini bertujuan untuk menangani keluhan klien terkait layanan Plesk pada shared hosting dan memastikan bahwa setiap masalah yang muncul dapat diidentifikasi dan diselesaikan dengan efektif dan efisien oleh tim IT Support dan Sys Admin.
Ruang Lingkup: Prosedur ini mencakup langkah-langkah yang dilakukan oleh tim IT Support dan Sys Admin dalam menangani keluhan klien terkait Plesk, termasuk identifikasi masalah, penanganan berbagai jenis masalah (disk rusak atau kurang, miskonfigurasi load balancer/proxy, serangan DDoS), serta koordinasi dengan tim SOC jika diperlukan.
Plesk: Panel kontrol untuk hosting web yang memudahkan pengelolaan server dan situs web.
IT Support: Tim yang bertanggung jawab menerima dan meneruskan keluhan klien.
Sys Admin: Tim yang bertanggung jawab untuk melakukan identifikasi dan penanganan teknis masalah yang muncul.
SOC (Security Operations Center): Tim yang menangani keamanan dan insiden terkait keamanan.
- 1IT Support menerima keluhan dari klien terkait layanan Plesk.
- 2IT Support meneruskan tiket keluhan ke Sys Admin.
- 3Sys Admin melakukan identifikasi awal penyebab masalah.
-
4Penanganan Berdasarkan Jenis Masalah
Sys Admin mengeksekusi solusi sesuai kategori masalah yang ditemukan.
Masalah Resource (Disk Penuh/Rusak):- Melakukan pengecekan penggunaan disk pada server Plesk.
- Membersihkan file log/sampah atau menambah kapasitas disk (Lihat prosedur Maintenance Storage).
Masalah Konfigurasi (Load Balancer/Proxy):- Memeriksa pengaturan reverse proxy (Nginx/Apache).
- Memperbaiki kesalahan konfigurasi pada Load Balancer.
- Merestart service web server jika diperlukan.
Masalah Keamanan (DDoS/Serangan Siber):- Sys Admin mengeskalasi insiden ke tim SOC.
- Tim SOC melakukan mitigasi (IP Filtering, Rate Limiting, atau Blocking).
- Memantau trafik hingga kembali normal.
- 5Sys Admin memverifikasi layanan kembali normal dan menginfokan ke IT Support.
- 6IT Support mengonfirmasi penyelesaian masalah kepada klien.
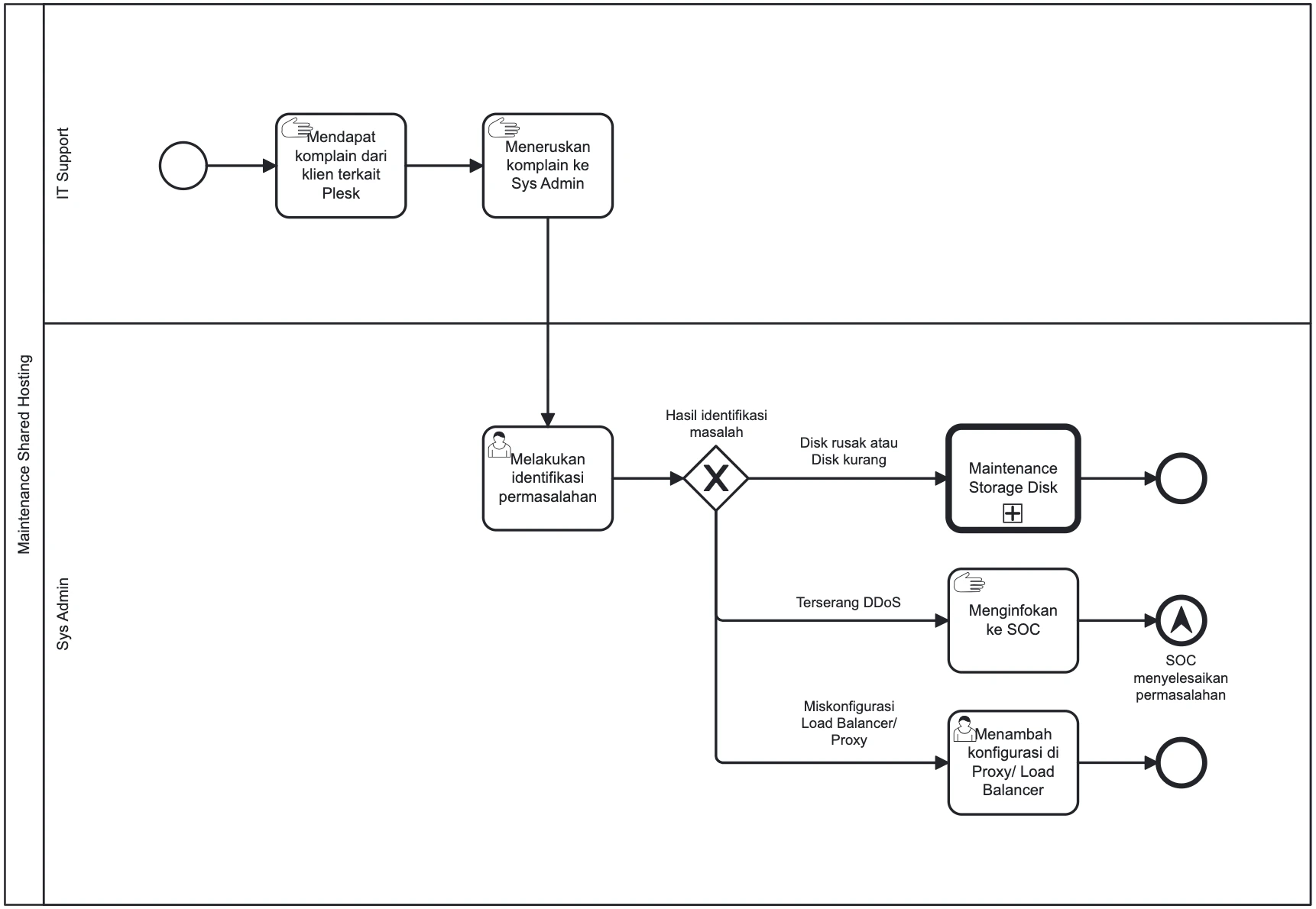
Gambar 6: Diagram Alur Kerja (BPMN) Maintenance Shared Hosting
Maintenance Switch
Prosedur pengecekan fisik dan dokumentasi perangkat switch jaringan untuk mencegah gangguan operasional.
Tujuan:
- Memastikan perangkat switch dalam kondisi fisik yang baik dan bersih.
- Memastikan kondisi perkabelan switch rapi dan berfungsi dengan baik.
- Mengidentifikasi kebutuhan maintenance yang memerlukan downtime untuk perbaikan atau perapian kabel.
- Memperbarui dokumentasi terkait kondisi switch secara berkala.
- Meminimalkan risiko gangguan operasional akibat kondisi switch yang buruk.
Ruang Lingkup:
- Koordinasi awal dengan PIC gedung untuk akses dan informasi.
- Pengecekan fisik switch (kebersihan, indikator, dll.).
- Pengecekan kondisi perkabelan switch (kerapian, kerusakan).
- Pengambilan keputusan apakah diperlukan penjadwalan maintenance dengan downtime atau hanya update dokumentasi.
- Pelaksanaan update dokumentasi.
- Proses ini tidak mencakup detail pelaksanaan maintenance yang membutuhkan downtime, hanya penjadwalannya.
Proses bisnis "Maintenance Switch" adalah serangkaian aktivitas yang dilakukan oleh Field Engineer untuk memastikan perangkat switch beroperasi secara optimal, aman, dan terdokumentasi dengan baik. Proses ini mencakup pengecekan fisik, kondisi perkabelan, serta penentuan tindakan selanjutnya berdasarkan hasil pengecekan.
- 1Field Engineer mendatangi lokasi switch dan berkoordinasi dengan PIC gedung untuk mendapatkan akses dan informasi yang diperlukan.
- 2Field Engineer melakukan pengecekan fisik switch, termasuk kebersihannya.
- 3Field Engineer melakukan pengecekan kondisi perkabelan switch.
-
4
Pengambilan Keputusan (Kondisi Perkabelan)
Tindakan selanjutnya ditentukan berdasarkan kerapian kabel.
Jika Kabel Tidak Rapi:- Field Engineer mencatat kebutuhan perbaikan.
- Menjadwalkan Maintenance Switch dengan Downtime untuk perapian kabel.
Jika Kabel Rapi:- Field Engineer memastikan tidak ada isu lain.
- Melakukan Update Dokumentasi kondisi switch saat ini.
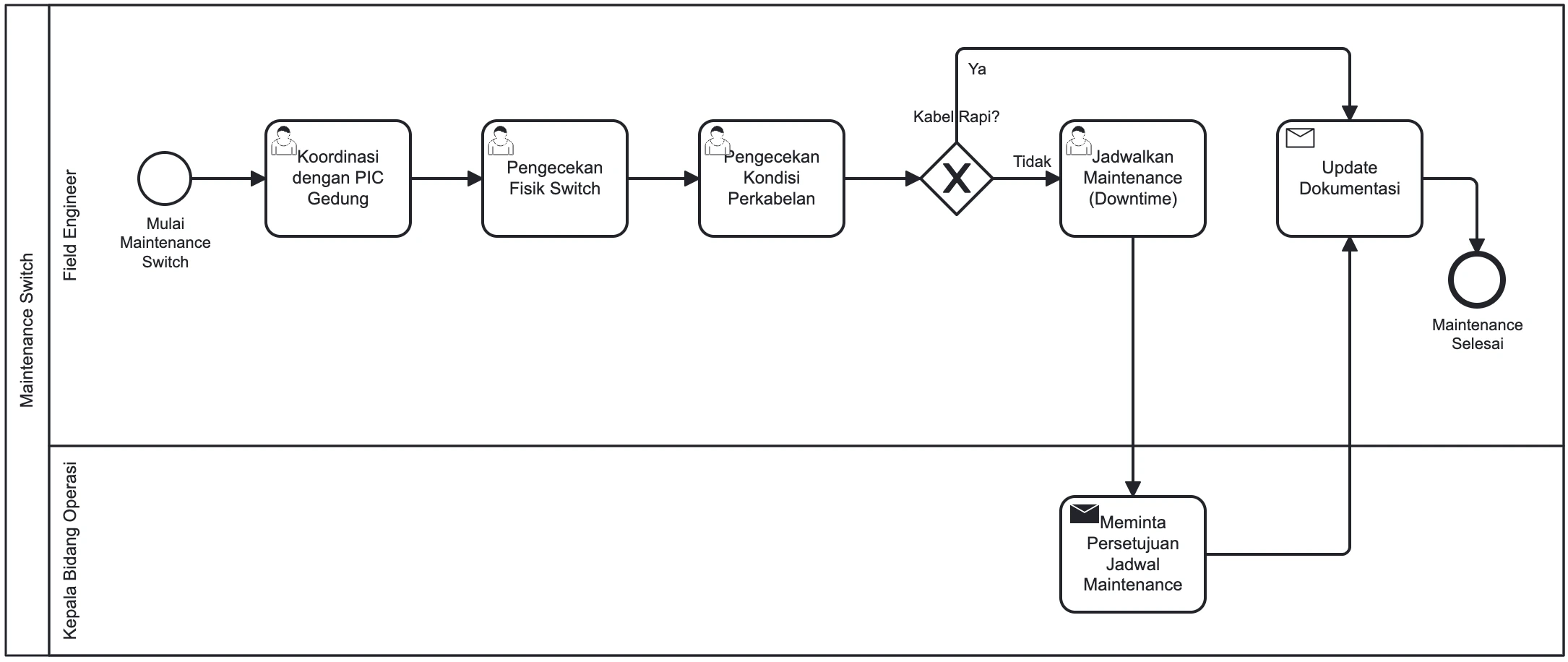
Gambar 7: Diagram Alur Kerja (BPMN) Maintenance Switch
Backup Database
Prosedur pencadangan data berkala menggunakan TrueNAS untuk menjamin keamanan dan pemulihan data.
Tujuan: Prosedur kerja ini bertujuan untuk melakukan backup database secara berkala dan terstruktur agar data tetap aman dan dapat dipulihkan dengan mudah jika terjadi kesalahan atau kehilangan data.
Ruang Lingkup: Prosedur ini mencakup langkah-langkah untuk melakukan backup database, baik untuk database standalone maupun cluster, menggunakan TrueNAS sebagai media penyimpanan.
NFS (Network File System): Sebuah protokol sistem berkas terdistribusi yang memungkinkan akses data melalui jaringan.
TrueNAS: Sistem operasi open-source berbasis FreeBSD yang dirancang untuk Network Attached Storage (NAS).
Snapshot: Salinan data pada titik waktu tertentu untuk mengembalikan kondisi data sebelumnya.
Cron Job: Penjadwal tugas otomatis untuk menjalankan perintah pada waktu tertentu.
Database Standalone: Database yang berjalan pada satu server tunggal.
Database Cluster: Sekumpulan server database yang saling terhubung untuk kinerja dan ketersediaan tinggi.
-
1
Persiapan Berdasarkan Tipe Database
DB Admin menentukan jenis database sebelum instalasi NFS.
Jika Database Standalone:- DB Admin langsung melakukan instalasi package NFS pada server database tersebut.
Jika Database Cluster:- DB Admin memilih salah satu node database dalam cluster sebagai sumber data backup.
- DB Admin melakukan instalasi package NFS pada server database yang terpilih tersebut.
- 2DB Admin membuat Cron Job pada TrueNAS untuk menjadwalkan proses backup secara otomatis.
- 3DB Admin membuat Snapshot database di TrueNAS sebelum proses backup dimulai (sebagai restore point).
- 4DB Admin menjalankan Cron Job secara manual untuk memulai proses backup pertama kali (inisiasi).
- 5DB Admin melakukan verifikasi untuk memastikan data backup telah berhasil tersimpan dan valid di TrueNAS.
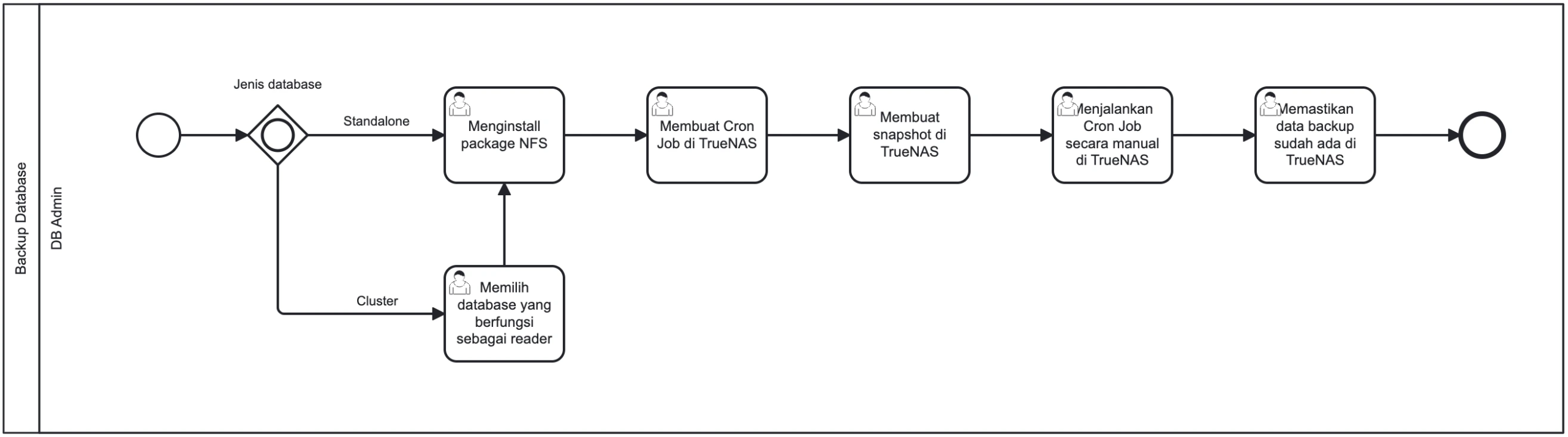
Gambar 8: Diagram Alur Kerja (BPMN) Backup Database
Backup Data (TrueNAS DC & DRC)
Prosedur backup, snapshot, dan replikasi data antar Data Center (DC) dan Disaster Recovery Center (DRC).
Tujuan: Mendefinisikan langkah-langkah dalam melakukan backup data menggunakan TrueNAS untuk memastikan keamanan dan ketersediaan data yang tersimpan di Data Center (DC) dan Disaster Recovery Center (DRC).
Ruang Lingkup: Mencakup proses instalasi, konfigurasi, dan eksekusi backup data menggunakan TrueNAS di lingkungan DC dan DRC.
TrueNAS: Sistem operasi open-source berbasis FreeBSD untuk Network Attached Storage (NAS).
DC (Data Center): Fasilitas fisik utama penyimpanan dan pengelolaan data.
DRC (Disaster Recovery Center): Lokasi alternatif untuk mengambil alih operasi jika terjadi bencana.
NFS (Network File System): Protokol jaringan untuk akses file jarak jauh.
SSH (Secure Shell): Protokol akses jarak jauh yang aman.
Snapshot: Salinan virtual sistem file pada waktu tertentu (restore point).
- 1Sys Admin menginstal TrueNAS di Data Center (DC) dan Disaster Recovery Center (DRC).
- 2Sys Admin membuat pool penyimpanan sesuai kebutuhan.
- 3Sys Admin mengaktifkan service NFS dan SSH.
- 4Sys Admin membuat sharing NFS sesuai kebutuhan akses.
- 5Sys Admin membuat Cron Job untuk penjadwalan tugas otomatis.
- 6Sys Admin menginstal paket
nfs-commondi VM yang akan dibackup. - 7Sys Admin mendaftarkan TrueNAS ke VM target backup.
- 8Sys Admin melakukan akses remote dari TrueNAS ke VM menggunakan SSH.
- 9Sys Admin melakukan uji coba (test running) Cron Job.
- 10Sys Admin memastikan Cron Job berjalan lancar tanpa error.
- 11Sys Admin mengatur jadwal Snapshot (Hourly, Daily, Weekly).
- 12Sys Admin membuat Replication Task dari TrueNAS DC ke TrueNAS DRC.
- 13Sys Admin memastikan pool di DRC dalam kondisi Read-Only (untuk integritas data backup).

Gambar 9: Diagram Alur Kerja (BPMN) Backup Data DC & DRC
Troubleshooting Kafka
Panduan penanganan masalah pada platform streaming data Kafka, mulai dari pengecekan log hingga restart komponen.
Tujuan: Memberikan panduan langkah-langkah troubleshooting Kafka di lingkungan sistem informasi untuk memastikan bahwa sistem berjalan dengan optimal dan masalah yang muncul dapat diatasi dengan cepat dan efisien.
Ruang Lingkup: Mencakup langkah-langkah yang harus diambil oleh tim Dev dan DB Admin saat menghadapi masalah pada sistem Kafka, termasuk pengecekan kondisi, penanganan kesalahan, dan penambahan resource jika diperlukan.
Kafka: Platform streaming data yang digunakan untuk membangun data pipelines dan aplikasi streaming real-time.
Rancher: Platform untuk mengelola kontainer Docker.
DB Admin: Administrator basis data yang bertanggung jawab atas pengelolaan dan pemeliharaan database.
Komponen Kafka: Mencakup Zookeeper, Broker, Kafka Connect, dan Schema Registry yang berperan penting dalam pengelolaan data.
- 1Tim Dev memeriksa kondisi Kafka apakah berjalan normal atau tidak.
-
2Investigasi Awal Tim Dev
- Jika kondisi tidak normal, periksa log di Kafka Connector.
- Jika log menunjukkan kesalahan yang bisa diperbaiki, lakukan Restart Kafka Connector.
- Jika masalah belum teratasi, periksa log pada query yang bersangkutan di Rancher.
- Jika terdapat error pada query, segera perbaiki query tersebut.
- 3Jika query tidak memiliki error atau masalah masih berlanjut, Tim Dev melaporkan ke DB Admin.
-
4Penanganan Lanjutan oleh DB Admin
DB Admin memeriksa resource dan log server Kafka.
Pengecekan Resource:Jika resource tidak mencukupi, DB Admin menambahkan resource pada Kafka Server.
Restart Komponen (Jika Diperlukan):DB Admin melakukan restart pada komponen berikut secara berurutan:
- Zookeeper
- Broker
- Kafka Connect
- Kafka Rest
- Schema Registry
- Web Kafka Connect
- Web Kafka Topic
- Web Schema Registry
- 5Setelah proses troubleshooting selesai, DB Admin mengirimkan hasilnya kembali ke Tim Dev.
- 6Tim Dev memeriksa dan memverifikasi hasil troubleshooting.
- 7Proses troubleshooting dianggap selesai setelah hasil pemeriksaan dinyatakan Baik oleh Tim Dev.
Gambar 10: Diagram Alur Kerja (BPMN) Troubleshooting Kafka
